What are Unique Molecular Identifiers (UMIs)?
Unique Molecular Identifiers (UMIs) are short random nucleotide sequences that are added during library generation (prior to PCR). UMIs act as tags that allow the accurate identification of PCR duplicates in sequencing data.
PCR duplicates can arise during library amplification if too many cycles are used and can therefore generate bias in sequencing read counts for downstream analysis of gene expression levels. Removing PCR duplicates can therefore remove any such biases.
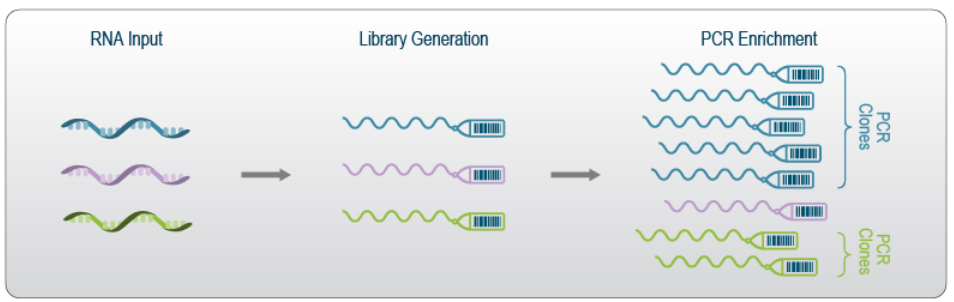
UMIs tag unique library inserts such that after PCR amplification, duplicates can be distinguished from unique transcript inserts.
When RNA-Seq libraries are generated from restricted regions of the transcript (e.g., in amplicon sequencing, in 3´mRNA libraries such as QuantSeq – which generates a 3' tag per transcript), there is a higher chance that identical priming occurs on unique transcripts or first strand cDNA molecules, than for whole-transcriptome RNA-Seq protocols which usually involve RNA fragmentation.
This results in sequencing reads originating from unique transcripts having identical mapping coordinates and sequences. Without UMIs, these reads would be wrongly classified as PCR duplicates and collapsed, resulting in inaccurate read count data.
Including UMIs during library generation clearly distinguishes unique priming events from PCR duplicates, and allows for accurate de-duplication of sequencing reads.
For QuantSeq FWD library prep, UMIs are added during second strand synthesis. With a length of 6 nucleotides, a total of 46, or 4,096, UMIs are possible.